


Apache Hudi: From Zero To One (10/10)
Becoming "One" - the upcoming 1.0 highlights

Apache Hudi: From Zero To One
Throughout the last nine posts, I have explored Hudi concepts pertinent to release 0.14, ideas that are relevant across most of the 0.x versions. For the blog series finale, I aim to cast a glance into the future and delve into the exciting new features in the upcoming 1.0 release. In doing so, this ending post will effectively accomplish the purpose of the series: guiding readers from the foundational beginnings to the groundbreaking future - from zero to one.
The Hudi Stack
Let's take a step back to our initial discussion in the first post and revisit the Hudi stack, a framework that has remained its relevance across both the 0.x and 1.x versions. Illustrated below, this stack functions on top of storage systems, executing read and write operations against open file formats. It is structured into three layers: the transactional database, the programming API, and the user interface.
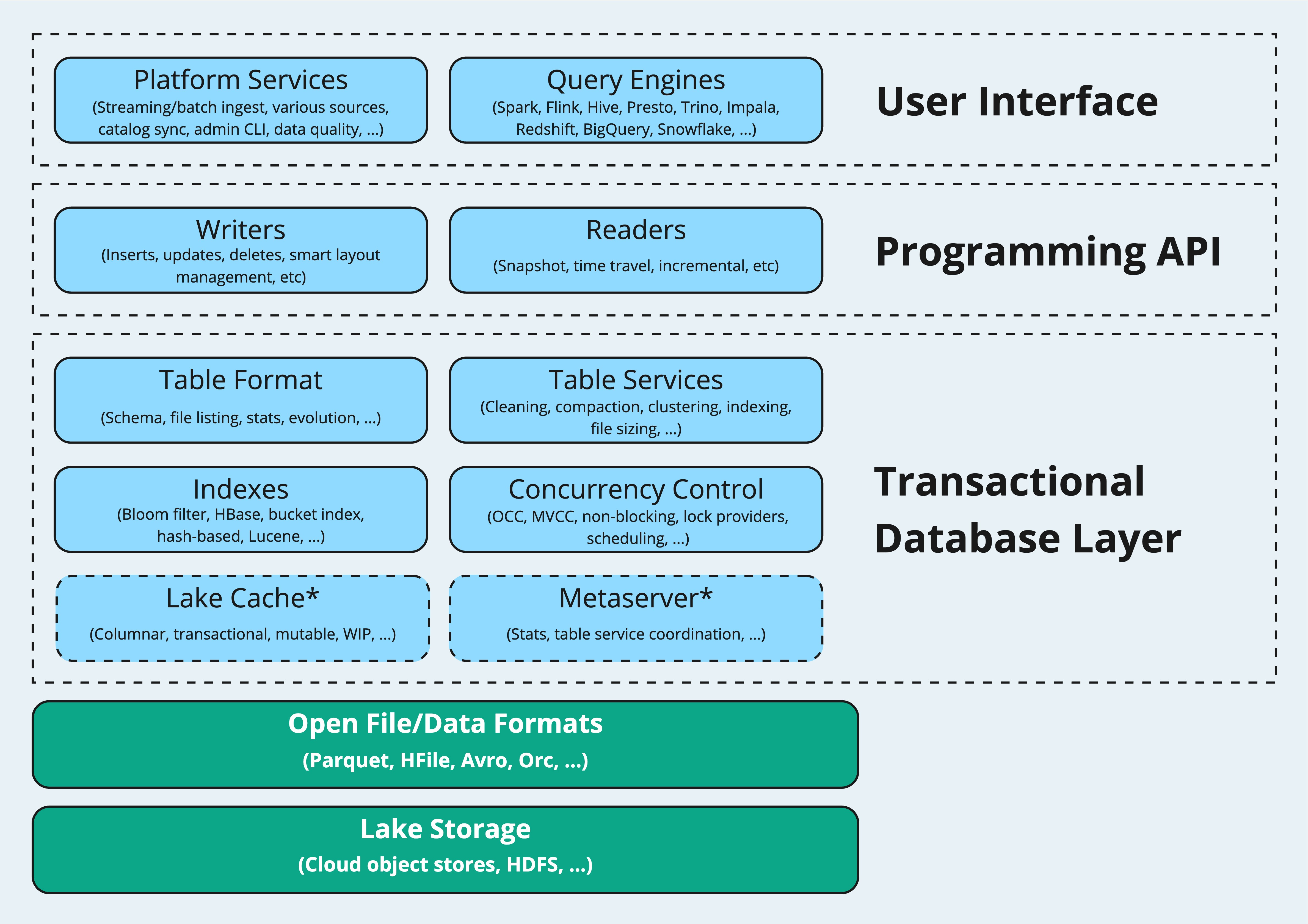
The transactional database layer, viewed as "the Hudi core", comprises several key components: the table format defines the storage layout, the table services keep the table optimized, the indexes speed up reads and writes, the concurrency control upholds the isolation principle, the lake cache elevates the read efficiency, and the metaserver centralizes the metadata access. These components act together to establish a robust foundation, delivering a database experience for Hudi Lakehouses.
The programming API layer introduces a suite of writer and reader interfaces, standardizing the integration with various execution and query engines. These APIs empower users across the ecosystem to fully harness Hudi's advanced capabilities such as efficient upserts and incremental processing.
The user interface layer provides a higher level of integrated tools that broadly fall into two categories: platform services, which include ingestion utilities, catalog sync tools, and admin CLI; and query engines such as Spark, Flink, Presto, Trino, among others. The diverse array of tools further aids users in adopting Hudi and building comprehensive Lakehouse solutions.
Release 1.0 Highlights
While the Hudi stack remains consistent in version 1.0, the new release features redesigns and updates at the table format level compared to the 0.x versions. These changes, along with other innovative new features, have enhanced overall efficiency and throughput, significantly upgrading Hudi Lakehouse's capabilities.
LSM Tree Timeline
The Hudi Timeline fundamentally consists of a series of immutable transaction logs that record all changes made to a table. In the 0.x versions, the volume of transaction logs increases linearly over time. To optimize storage use, older Timeline instants are archived for optimizing the storage while at the cost of increased compute during access. For Hudi 1.0, a key design goal is to support a near-infinite Timeline that balances optimized storage with efficient access. To achieve this, Log-Structured Merge-Tree (LSM Tree) is adopted to define the Timeline layout in 1.0 tables.
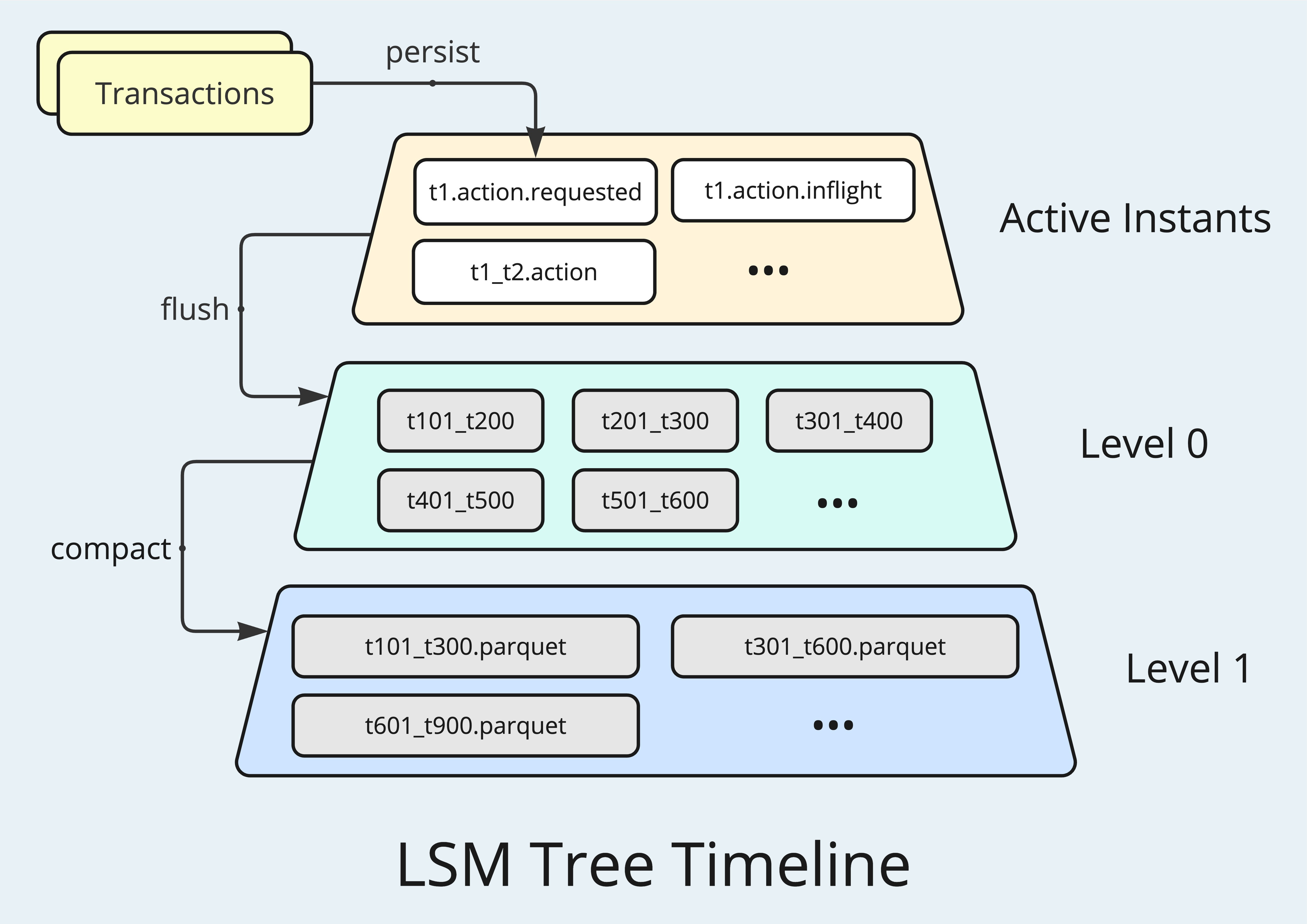
LSM Tree is a multi-layered data structure designed for high write throughput. At the top layer, Hudi Timeline stores the transactions as active instants, having individual Avro files recording the metadata for each transaction's states: requested, inflight, and completed. When exceed a certain threshold, the active instants will be flushed to Parquet files, forming the first storage-optimized layer. The transactions are grouped and sorted chronologically, and the file names contain time range information, allowing efficient retrieval through manifest files. When the number of Parquet files stored at one level exceeds a certain limit, the files will be compacted and pushed down to the next level as larger files with more Timeline instants, further improving storage efficiency. Additionally, these highly compressed Parquet files are optimized for query performance, particularly when time-range filters or specific columns are targeted, ensuring fast data retrieval.
Non-Blocking Concurrency Control
When a streaming writer is present in a concurrent writing scenario, contention could frequently arise due to random updates (e.g., running a separate GDPR deleter job). Using Optimistic Concurrency Control (OCC) in such scenario can lead to repeated retries, thereby wasting compute resources. Hudi has adopted Multi-Version Concurrency Control (MVCC) to prevent blocking and retry behaviors due to contention among a single-writer and table service runners. Hudi also offers early conflict detection for OCC to reduce resource wastage upon retries. To advance further, Hudi 1.0 introduces Non-Blocking Concurrency Control (NBCC) for MOR tables to maximize writer throughput.
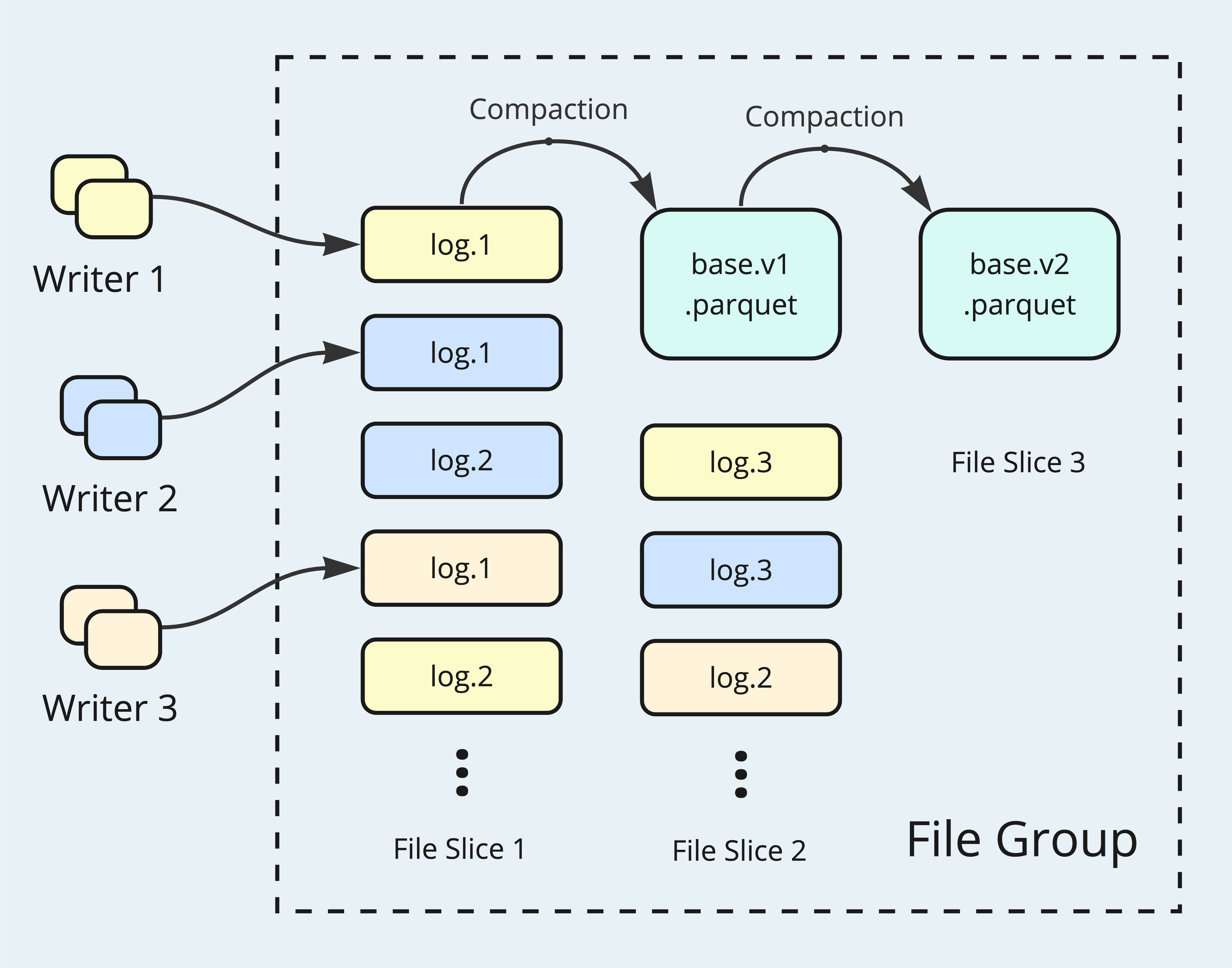
NBCC allows multiple writers to persist updating Log Files freely to the same File Slice, and defers the conflict resolution to the compaction stage. Different from the 0.x versions, Log Files in 1.0 also record commit completion time in addition to the starting time. This new piece of information enables proper sorting for the Log Files and helps determine File Slice boundaries. Merging semantics based on a configurable ordering field are applied to the updating records during compaction. To resolve the clock skew issue, TrueTimeGenerator is implemented to ensure monotonically increasing timestamps for all writers' commits.
File Group Reader & Writer
Since the very beginning, Hudi has incorporated the concept of record keys, a design choice that unlocks significant potential for record level operations. Paired with the File Group model, this approach lays a robust foundation for efficient upserts and look-ups. In Hudi 1.0, File Group Reader and Writer APIs are introduced to fully capitalizes on the design advantages offered by the record keys and the File Group model.
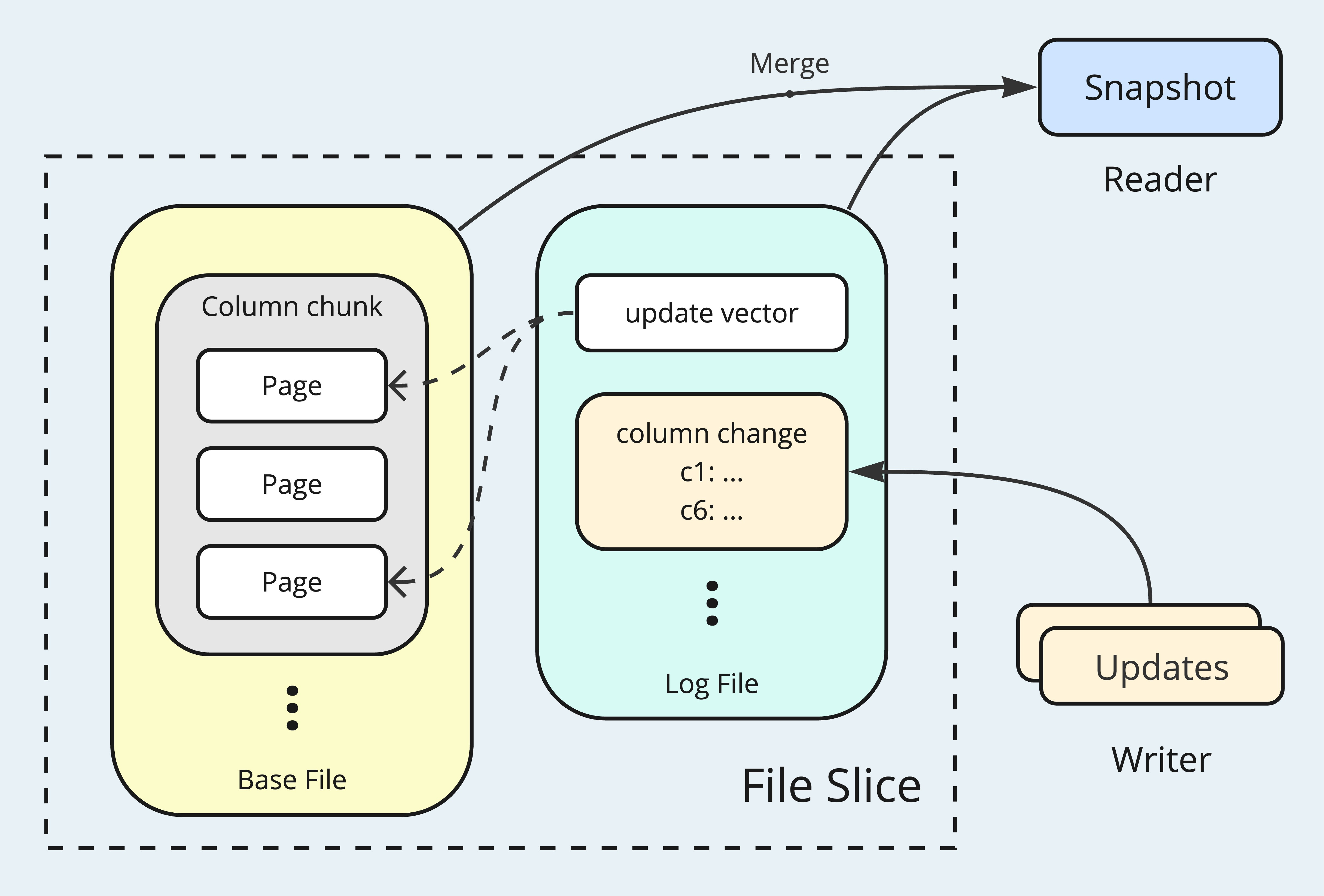
On the writer side, Hudi 1.0 employs partial updates, which involve only the updated columns and values, to greatly reduce the Log File sizes. By leveraging Hudi's advanced indexing systems, records targeted for updates are efficiently located, and positional information can be encoded alongside the data log blocks. On the reader side, having the minimized Log File data and the positional information to pinpoint the updating rows and columns, a snapshot query against an un-compacted File Slice can be fully optimized.
Functional Index
In the 0.x versions, Hudi has supported a variety of indexing capabilities, including the Bucket Index and Record-level Index, among others. To enhance flexibility and improve access speeds, Hudi 1.0 introduces the Functional Index, enabling faster retrieval methods and incorporating partitioning schemes into the indexing system.
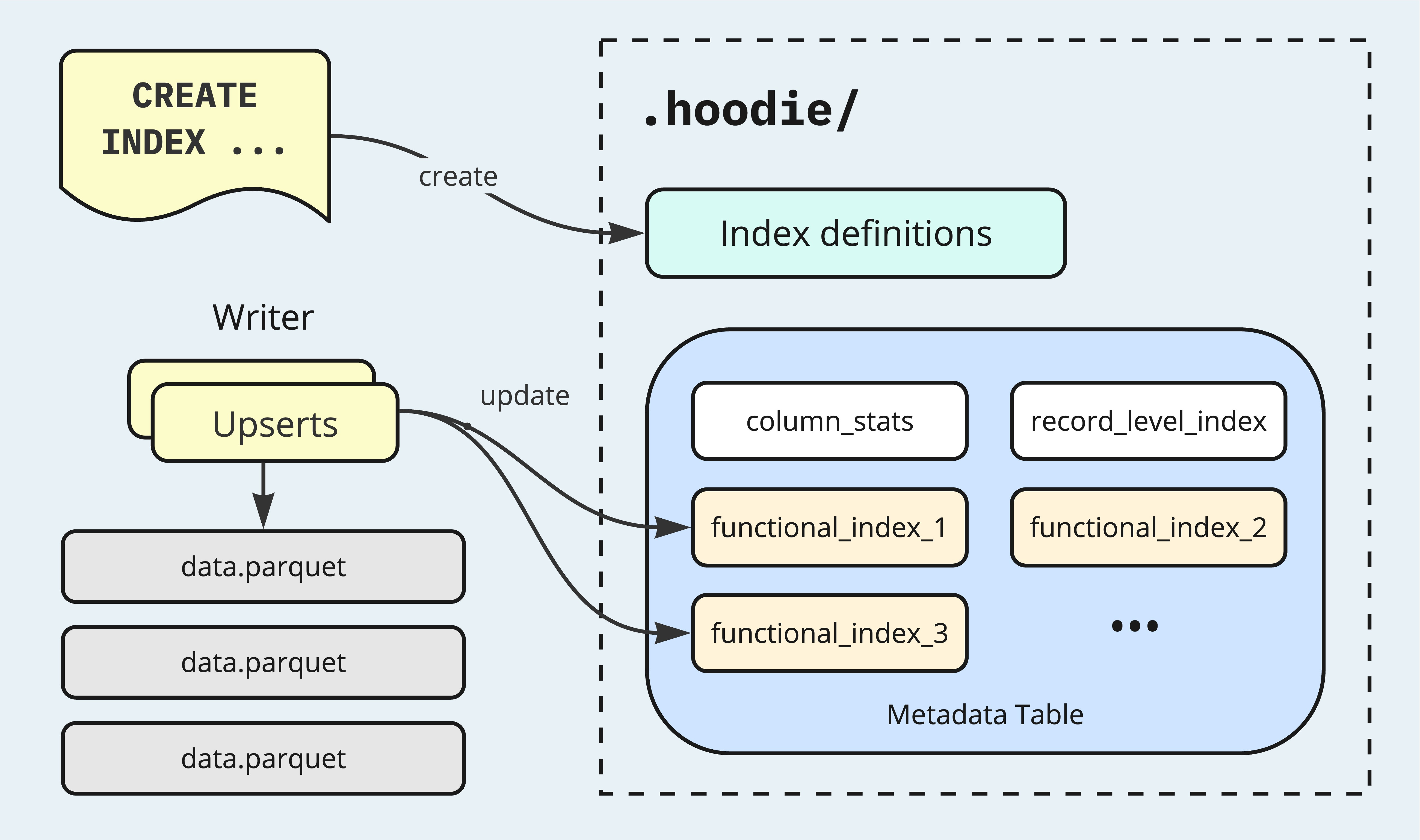
For example, consider a column "ts" that holds Epoch timestamps. Users might want to filter the data by different time precisions, such as monthly or hourly. By building a Functional Index on the "ts" column using the following SQL, it's possible to achieve effective data-skipping without the need to physically partition the table by hour or add a separate "hour" column.
CREATE INDEX ts_hour ON hudi_table USING column_stats(ts) options(func='hour');Hudi stores user-created index definitions under a dedicated directory under the metadata path .hoodie/. These definitions inform query engines about the available indexes, facilitating more optimized query planning. The index entries are maintained under separate partitions within the Metadata Table, which serves as the indexing subsystem for the enclosing Hudi table. When writers commit changes, all the available Functional Indexes are updated to reflect these changes, in a manner similar to other enabled indexing features in the Metadata Table. This ensures that indexes remain up-to-date, maintaining high levels of efficiency for both read and write operations.
Recap
In this post, we revisited the Hudi stack diagram, and introduced four noteworthy features set to debut in the upcoming 1.0 release: the LSM Tree Timeline, Non-Blocking Concurrency Control, File Group Reader & Writer, and the Functional Index. In short, Hudi 1.0 makes a defining release, setting a new standard in its development trajectory. As a closing note, here is a key excerpt from the 1.x RFC that succinctly captures the essence of this significant upgrade:
We propose Hudi 1.x as a reimagination of Hudi, as the transactional database for the lake, with polyglot persistence, raising the level of abstraction and platformization even higher for Hudi data lakes.
Apache Hudi has a thriving community - come and engage with us via Slack, GitHub, LinkedIn, X (Twitter), and YouTube!