

Apache Hudi: From Zero To One (2/10)
Dive into read operation flow and query types

Apache Hudi: From Zero To One
In the previous post, we discussed the data layout within a Hudi table and introduced the two table types, CoW and MoR, along with their respective trade-offs. Building on that, we will now explore how read operations work in Hudi.
There are several engines, such as Spark, Presto, and Trino, integrated with Hudi that enable you to execute analytical queries. Although the integration APIs may differ, the fundamental process in distributed query engines remains consistent. This process entails interpreting the input SQL, creating a query plan for execution on worker nodes, and collecting the results to return to users.
In this post, I have selected Spark1 as the example engine to illustrate the flow of read operations and provide code snippets to showcase the usage of various Hudi query types. I will begin by introducing Spark queries with a primer, then delve into the Hudi-Spark integration points, and finally, explain the different query types.
Spark Query Primer
Spark SQL is a distributed SQL engine that performs analytical tasks for large-scale data. A typical analytics query begins with user-provided SQL, aiming to retrieve results from a table on storage. Spark SQL takes this input and proceeds through multiple phases, as depicted in the diagram below.
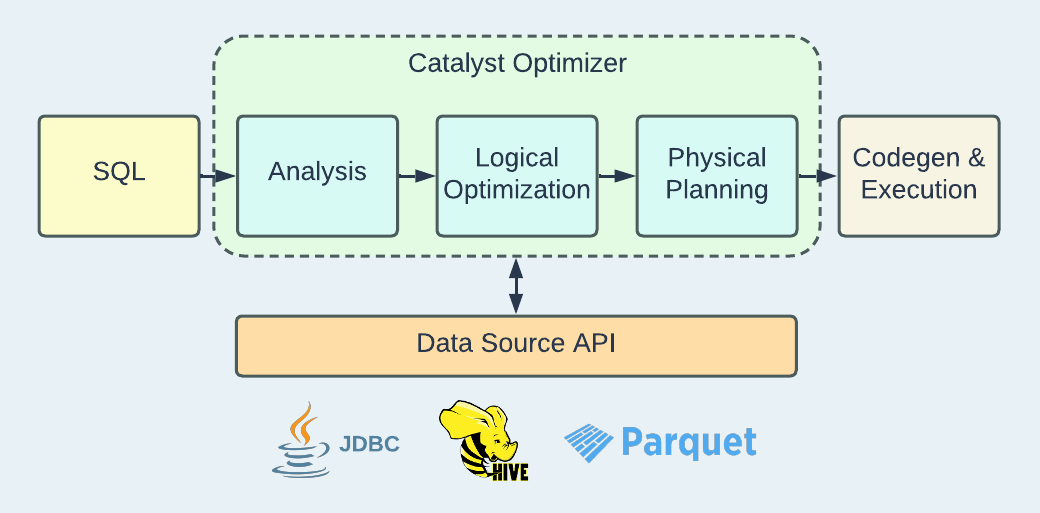
During the analysis phase, the input is parsed, resolved, and converted into a tree structure that works as an abstraction of the SQL statement. The table catalog is consulted for information such as table names and column types.
At the logical optimization step, the tree is evaluated and optimized at the logical layer. Some common optimizations include predicate pushdown, schema pruning, and null propagation. This step generates a Logical Plan that outlines the necessary computations for the query. Since it is a logical representation, the Logical Plan lacks the specifics needed for running on actual nodes.
Physical planning serves as the bridge between the logical layer and the physical layer. A Physical Plan specifies the precise manner in which computations should be executed. For instance, in a Logical Plan, there may be a join node indicating a join operation, whereas in the Physical Plan, the join operation could be specified as a sort-merge join or a broadcast-hash join, depending on size estimates from the relevant tables. The optimal Physical Plan is selected for code generation and actual execution.
The three phases are features provided by Catalyst Optimizer. For further study on this topic, you may explore excellent talks like the ones linked here and here.
During execution, a Spark application operates on the foundational data structure known as RDD (Resilient Distributed Dataset). RDDs are collections of JVM objects that are immutable, partitioned across nodes, and fault-tolerant due to the tracking of data lineage information. As the application runs, the planned computations are performed: RDDs are transformed and acted upon to produce results. This process is also commonly referred to as "materializing" the RDDs.
Data Source API
While Catalyst Optimizer is formulating query plans, connecting to the data source becomes advantageous, enabling optimizations to be pushed down. Spark's Data Source API is designed to provide extensibility for integrating with a wide range of data sources. Some sources are supported out-of-the-box, such as JDBC, Hive tables, and Parquet files. Hudi tables, owing to the specific data layout, represent another type of custom data source.
Spark-Hudi Read Flow
The diagram below illustrates some key interfaces and method calls in the Spark-Hudi read flow.
DefaultSourceserves as the entry point of the integration, defining the data source’s format asorg.apache.hudiorhudi. It provides aBaseRelation, which Hudi uses to implement the data extraction process.buildScan()is a core API to pass filters to data sources for optimizations. Hudi definescollectFileSplits()for gathering relevant files.collectFileSplits()passes all the filters to aFileIndexobject that helps identify the necessary files to read.FileIndexlocates all the relevantFileSlices for further processing.composeRDD()is invoked afterFileSlices are identified.FileSlices are loaded and read out asRDDs. For columnar files like Base Files in Parquet, this read operation minimizes the transferred bytes by reading only the necessary columns.RDDs are returned from the API for further planning and code generation.
Please note that the steps mentioned above provide only a high-level overview of the read flow, omitting details such as support for schema-on-read and advanced indexing techniques like data skipping using a metadata table.
The flow is common to all Hudi query types with Spark2. In the following sections, I will explain how the various query types work. All of them, except for Read-Optimized, are applicable to both CoW and MoR tables.
Snapshot Query
This is the default query type when reading Hudi tables. It aims to retrieve the latest records from the table, essentially capturing a "snapshot" of the table at the time of the query. When performed on MoR tables, the merging of Log Files with the Base File occurs and results in some performance impact.
After launching a spark-sql shell with Hudi dependency3, you may run these SQLs to setup a MoR table with one record inserted and updated.
create table hudi_mor_example (
id int,
name string,
price double,
ts bigint
) using hudi
tblproperties (
type = 'mor',
primaryKey = 'id',
preCombineField = 'ts'
) location '/tmp/hudi_mor_example';
set hoodie.spark.sql.insert.into.operation=UPSERT;
insert into hudi_mor_example select 1, 'foo', 10, 1000;
insert into hudi_mor_example select 1, 'foo', 20, 2000;
insert into hudi_mor_example select 1, 'foo', 30, 3000;You can execute a snapshot query by running a SELECT statement as shown below, and it will retrieve the latest value of the record.
spark-sql> select id, name, price, ts from hudi_mor_example;
1 foo 30.0 3000
Time taken: 0.161 seconds, Fetched 1 row(s)Read-Optimized (RO) Query
RO query type is designed as a trade-off for lower read latency with potentially older results, and therefore, it is exclusively applicable to MoR tables. When conducting such queries, collectFileSplits() will only fetch Base Files for FileSlices.
The provided setup code above automatically generates a catalog table named hudi_mor_example_ro, which specifies a property hoodie.query.as.ro.table=true. This property instructs query engines to always perform RO queries. Running the SELECT statement below returns the original value of the record since the subsequent updates have not yet been applied to the Base File.
spark-sql> select id, name, price, ts from hudi_mor_example_ro;
1 foo 10.0 1000
Time taken: 0.114 seconds, Fetched 1 row(s)Time Travel Query
By specifying a timestamp, users can request a historical snapshot of a Hudi table at the given time. As previously discussed in post 1, FileSlices are associated with specific commit times and, therefore, support filtering. When performing time travel queries, the FileIndex locates only the FileSlices that correspond to, or are just older than, the specified time if there is no exact match.
spark-sql> select id, name, price, ts from hudi_mor_example timestamp as of '20230905221619987';
1 foo 30.0 3000
Time taken: 0.274 seconds, Fetched 1 row(s)
spark-sql> select id, name, price, ts from hudi_mor_example timestamp as of '20230905221619986';
1 foo 20.0 2000
Time taken: 0.241 seconds, Fetched 1 row(s)The first SELECT statement executes a time travel query precisely at the deltacommit time of the latest insert, providing the most recent snapshot of the table. The second query sets a timestamp earlier than the latest insert’s, resulting in a snapshot as of the second-to-last insert.
The timestamp in the example follows the Hudi Timeline’s format 'yyyyMMddHHmmssSSS'. You may also set it in the form of 'yyyy-MM-dd HH:mm:ss.SSS' or 'yyyy-MM-dd'.
Incremental Query
Users can set a starting timestamp, with or without an ending timestamp, to retrieve changed records within the specified time window. If no ending time is set, the time window will include the most recent records. Hudi also offers full Change-Data-Capture (CDC) capabilities by enabling additional logs on the writer's side and activating CDC mode for incremental readers. Further details will be covered in a separate post dedicated to incremental processing.
Recap
In this post, we provided an overview of Spark's Catalyst Optimizer, explored how Hudi implements the Spark Data Source API for reading data, and introduced four distinct Hudi query types. In the upcoming post, I will demonstrate the write flow to further enhance our understanding of Hudi. Please feel free to share your feedback and suggest content in the comments section.
Apache Hudi has a thriving community - come and engage with us via Slack, GitHub, LinkedIn, X (Twitter), and YouTube!
Versions used: Spark 3.2, Scala 2.12, Hudi 0.14
Incremental queries have a slightly different flow on the Hudi internals, where FileIndex may not be involved for locating FileSlices.
The Hudi quick-start guide has the detailed steps.
are you going to upload posts from 5-10th?
Hi Shiyan Xu, great post, can't wait to read the next one!
Do you plan to explore the cost savings/overhead associated to Hudi?
I am wondering if CoW and MoR, in cloud environment, entail raise in cost for storage and processing. A huge question made when I propose Hudi as a solution is how is it different from parquet in terms of cost on HDFS like file systems in cloud enviroment, considered that you can have multiple snapshot of a table, you need to merge/copy files and so on. I see a lot of comparison between delta, hudi and iceberg in terms of performances but cost aren't explored at all.
Imho it is importanto to explore costs also because often the goal is to replace a DWH with a cheaper solution, if any.
Thanks