



Apache Hudi: From Zero To One (1/10)
A first glance at Hudi's storage format

Apache Hudi: From Zero To One
After dedicating approximately 4 years to working on Apache Hudi, including 3 years as a committer, I decided to start this blog series with the intention of presenting Hudi's design and usage in an organized and beginner-friendly manner. My aim is to ensure the series is easy to follow for people with some knowledge of distributed data systems. The series will comprise 10 posts, each delving into a key aspect of Hudi. (Why 10? Purely a playful nod to 0 and 1, echoing the series title :) ) The ultimate goal is to help readers understand Hudi with both breadth and depth, enabling them to confidently utilize and contribute to this open-source project.1
Hudi Overview
Hudi is a transactional data lake platform that brings database and data warehouse capabilities to the data lake. The Hudi stack shown below clearly illustrates the major features of the platform.
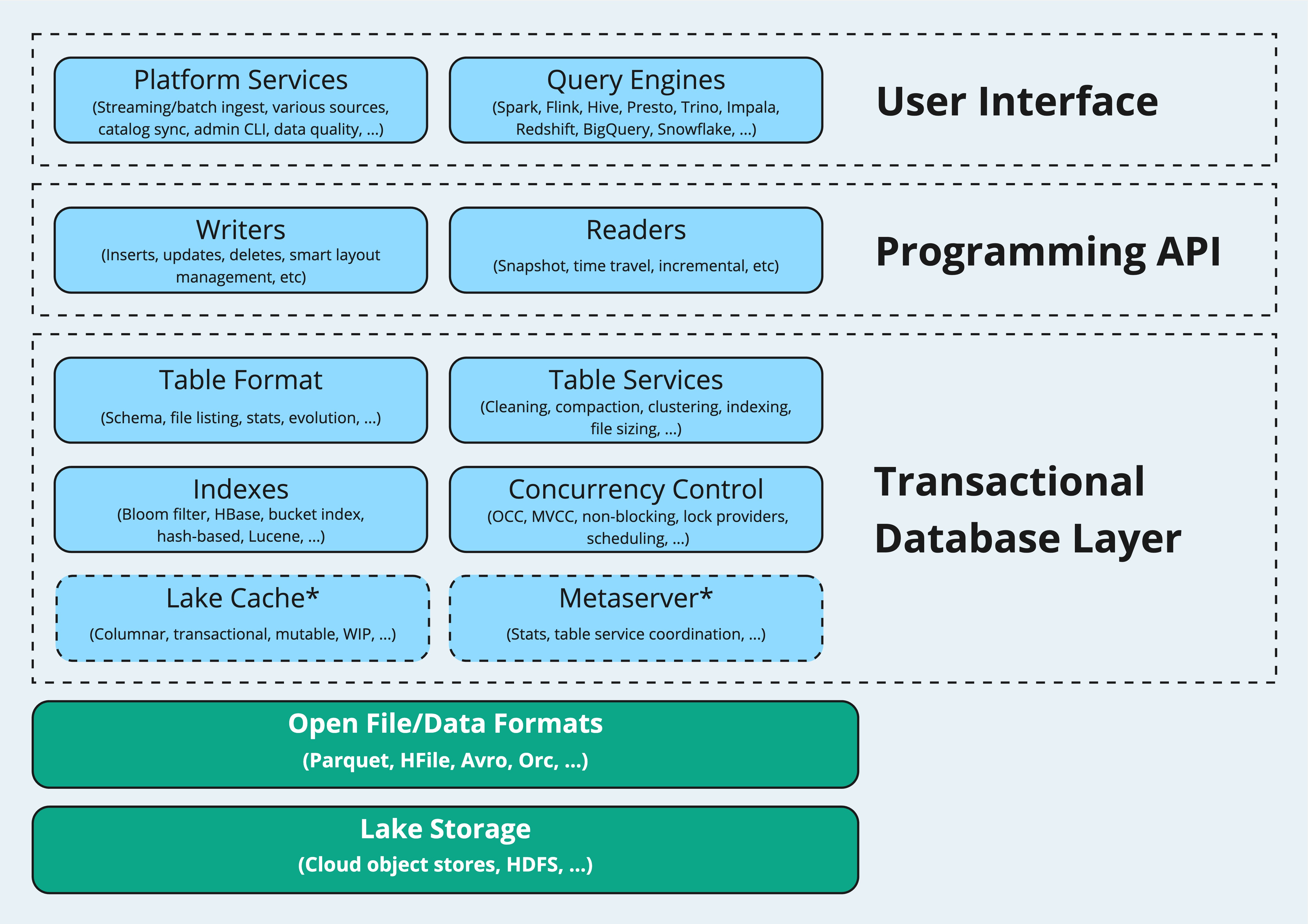
At its core, Hudi defines a table format that organizes the data and metadata files within storage systems, allowing for features such as ACID transactions, efficient indexing, and incremental processing to be achieved. The remainder of this post will explore the format details, essentially showcasing the structure of a Hudi table on storage and explaining the roles of different files.
Storage Format
The diagram below depicts a typical data layout of a Hudi table under the table's base path in storage.

There are two main types of files:
Metadata files located in
<base_path>/.hoodie/Data files stored within partition paths for partitioned tables, or under the base path for non-partitioned tables
Metadata
The <base path>/.hoodie/hoodie.properties file contains essential table configurations, such as table name and version, which both writers and readers of the table will adhere to and utilize.
Alongside hoodie.properties, there are meta-files that record transactional actions to the table, forming the Hudi table's Timeline.
# an example of deltacommit actions on Timeline
20230827233828740.deltacommit.requested
20230827233828740.deltacommit.inflight
20230827233828740.deltacommitThese meta-files follow the naming pattern below:
<action timestamp>.<action type>[.<action state>]The <action timestamp>
marks when an action was first scheduled to run.
uniquely identifies an action on Timeline.
is monotonically increasing across different actions on a Timeline.
The <action type> shows what kind of changes were made by the action. There are write action types, such as commit and deltacommit, which indicate new write operations (insert, update, or delete) that occurred on the table. Additionally, there are table service actions, such as compaction and clean, as well as recovery actions like savepoint and restore. We will discuss different action types in more detail in future posts.
The <action state> can be requested, inflight, or completed (without a suffix). As the names suggest, requested indicates being scheduled to run, inflight means execution in progress, and completed means that the action is done.
The meta-files for these actions, in JSON or AVRO format, contain information about the changes that should be applied to the table or that have been applied. Keeping these transaction logs makes it possible to recreate the table's state, achieve snapshot isolation, and reconcile writer conflicts through concurrency control mechanisms.
There are other metadata files and directories stored under .hoodie/. To give some examples, the metadata/ contains further metadata related to actions on the Timeline and serves as an index for readers and writers. The .heartbeat/ directory stores files for heartbeat management, while the.aux/ is reserved for various auxiliary purposes.
Data
Hudi categorizes physical data files into Base File and Log File:
Base File contains the main stored records in a Hudi table and is optimized for read.
Log File contains the records' changes on top of its associated Base File and is optimized for write.
Within a partition path of a Hudi table (as shown in the previous layout diagram), a single Base File and its associated Log Files (which can be none or many) are grouped together as a File Slice. Multiple File Slices constitute a File Group. Both the File Group and the File Slice are logical concepts designed to enclose physical files, simplifying access and manipulation for both readers and writers. By defining these models, Hudi can
fulfill both read and write efficiency requirements. Typically, Base File is configured as a columnar file format (e.g., Apache Parquet) and Log File is set to a row-based file format (e.g., Apache Avro).
achieve versioning across commit actions. Each File Slice is tied to a specific timestamp of an action on the Timeline, and the File Slices within a File Group essentially track how the contained records evolved over time.
Table Types
Hudi defines two table types - Copy-on-Write (CoW) and Merge-on-Read (MoR). The layout differences are as follows: CoW has no Log File compared to MoR, and write operations result in .commit actions instead of .deltacommit. Throughout our discussion, we have been using MoR as the example. Understanding CoW becomes straightforward once you grasp MoR - you can treat CoW as a special case of MoR where records in a Base File and the changes are implicitly merged into a new Base File during each write operation.
When choosing the table type for a Hudi table, it is important to take into account the read and write patterns, as there are some implications:
CoW has high write amplification due to rewriting records in the new File Slices for every write, while read operations will always be optimized. This is well-suited for read-heavy analytical workloads or small tables.
MoR has low write amplification because changes are buffered in Log Files and batch-processed to merge and create new File Slices. However, read latency is affected since inflight merging of Log Files with Base File is required for reading the latest records.
Users may also opt to only read Base Files of an MoR table to obtain efficiency while sacrificing result freshness. We will discuss more about Hudi's different read modes in forthcoming posts. As the Hudi project evolves, the merging costs associated with reading from MoR tables has been optimized over past releases. It is foreseeable that MoR will become the preferred table type for most workload scenarios.
Recap
In this initial post of the zero-to-one series, we have explored the fundamental concepts of Hudi's storage format to elucidate how metadata and the data are structured within Hudi tables. We also briefly explained the different table types and their trade-offs. As shown in the overview diagram, Hudi serves as a comprehensive lakehouse platform offering features across various dimensions. In the upcoming nine posts, I will progressively cover other significant facets of the platform. Please don't hesitate to share your feedback and suggest content in the comments section.
Apache Hudi has a thriving community - come and engage with us via Slack, GitHub, LinkedIn, X (Twitter), and YouTube!
The concepts introduced in the series will be based on 0.14.0, the latest version at the time of writing.



![byte[array]'s avatar](https://substackcdn.com/image/fetch/w_96,h_96,c_fill,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F920b88a0-b456-49b5-9189-9cdee041abe5_1457x1615.png)



Nice and waiting for next series