


Apache Hudi: From Zero To One (4/10)
All about writer indexes

Apache Hudi: From Zero To One
In the previous post, we walked through Hudi’s write operation flow. Among all the steps involved, indexing is a crucial one that verifies the existence of records in the table and helps achieve efficient update and delete operations. This post will introduce the indexing APIs and explore various types of indexes. Please note that the indexes covered in this post are intended for writers, which differs from reader-side indexing.1
Indexing APIs
Writer indexing abstractions are defined in HoodieIndex. I'll describe some key APIs below to provide a high-level understanding of what indexing entails.
tagLocation(): when a set of input records is passed to the index component during writing, this API is invoked to tag each record, determining whether it is present in the table, and then associating it with its location information. The resulting set of records is referred to as "tagged records". In the HoodieRecord model, the "currentLocation" field will be populated by this tagging process.updateLocation(): after writing to storage, certain indexes require location information to be updated to synchronize with the data table. This process is only executed during the post-IO phase for those applicable index types.isGlobal(): Hudi categorizes indexes into global and non-global types. Global indexes identify unique records across all table partitions, hence being "global" in relation to the table. Non-global indexes, on the other hand, validate uniqueness at the partition level. Typically, non-global indexes exhibit better performance due to their smaller scan space. However, they are not suitable for tables with records that can shift between partitions.canIndexLogFiles(): due to the implementation specifics, certain indexes are able to index on Log Files for Merge-on-Read tables. This characteristic affects how writers create file-writing handles: when this is true for the configured index, inserts will be routed to Log Files throughAppendHandle.isImplicitWithStorage(): this is a characteristic that indicates whether the index is implicitly "persisted" along with data files on storage. Some indexes store their indexing data separately.
Index Types
Hudi offers several out-of-the-box index types to suit different traffic patterns and table sizes. Selecting the most appropriate index for each table is a crucial tuning step. This article well-explains the significance of making the right choices. In the following sections, I will illustrate the internal workings of writer indexes to enhance understanding.
Simple Index
The Simple Index is a non-global index and currently serves as the default type. The primary concept behind it involves scanning all Base Files within the relevant partitions to determine whether incoming records match any of the extracted keys.
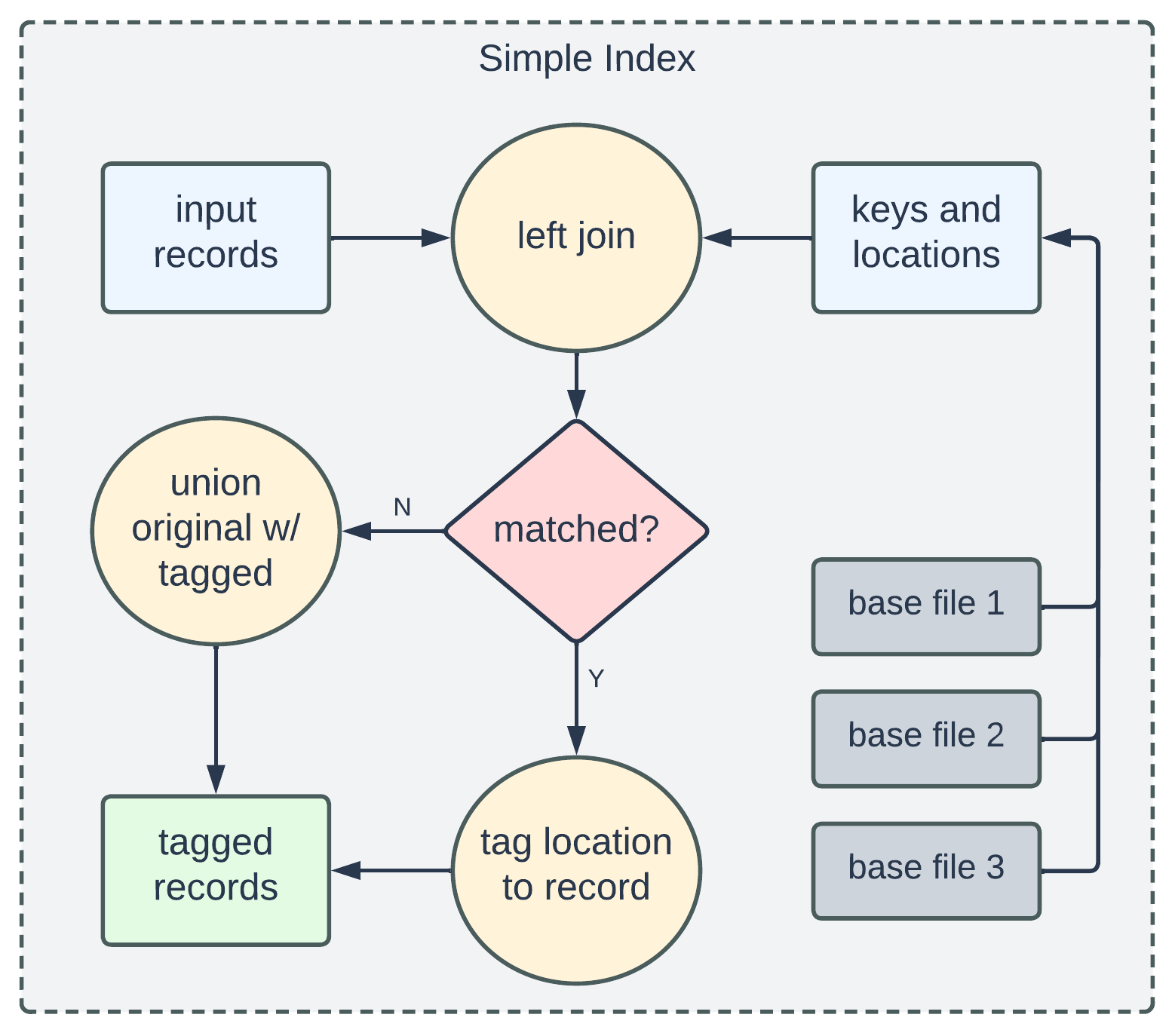
From the left-join operation, if an input record matches an extracted key, the join result will include the location information, which will then be used to populate the "currentLocation" field of the HoodieRecord. This produces the so-called "tagged records". Those unmatched records will be kept as-is and union-ed with the tagged records for further processing.
The Simple Index has a global version known as the Global Simple Index. Unlike its non-global counterpart, it matches input against Base Files from all partitions rather than just the relevant ones. When a record's partition value is updated, the respective File Group is loaded, which also includes Log Files for MoR tables, for an additional tagging step: it merges the incoming record with its existing old version and tags the merged result to the location in the new partition.
Since the Simple Indexes tend to load all Base Files at either the partition level or the table level, they are well-suited for traffic patterns having random or evenly-distributed data access.
Bloom Index
The Bloom Index follows a similar high-level flow to the Simple Index. However, the distinguishing concept behind the Bloom Index lies in its approach to minimizing the number of keys and files for look-ups while maintaining a low read cost.
The Bloom Index employs a 2-stage filtering to reduce the number of keys and files for look-ups.
The first stage involves comparing input keys against an interval tree constructed using minimum and maximum record key values stored in Base Files’ footers. Keys falling out of these ranges represent the new inserts, while the remaining keys are considered candidates for the next stage.
The second stage checks the candidate keys against deserialized Bloom filters, which help determine the definitively absent keys and the potentially present keys. Actual file look-ups are then carried out using the filtered keys and the associated Base Files, which subsequently return the key and location tuples for tagging.
Please note that the filtering process before the look-ups only involves reading the file footers, thereby incurring low read costs.
Just like the Simple Index, the Bloom Index also has a global version known as the Global Bloom Index. It operates similarly to the non-global version, albeit at the table level, and employs the same logic as the Global Simple Index for handling partition-update scenarios.
Bucket Index
The Bucket Index is designed based on hashing, allowing us to consistently map a key to a File Group using a fixed hashing function, eliminating the need for any disk reads and resulting in significant time savings.
The Bucket Index comes in two variations - the Simple Bucket Index and the Consistent Bucket Index. The Simple Bucket Index assigns a fixed number of buckets, each mapping to one File Group, which in turn limits the total number of File Groups in the table. This leads to drawbacks on handling data skewness and scaling out.
On the other hand, the Consistent Bucket Index is designed to overcome the drawbacks by dynamically re-hashing an existing bucket into sub-buckets when the corresponding File Group exceeds a certain size threshold.
HBase Index
The HBase Index is implemented using an externally running HBase server. It stores the mappings between a record key and the relevant File Group information, and it is a global index. This offers efficient look-ups for tagging in most cases and can readily scale out as the table size increases. However, the drawback is the operational overhead involved in managing an additional server.
Record Index
The Record Index is a newly added feature in release 0.14.0 and operates logically similar to the HBase Index: it is also a global index that saves the mappings of record keys and File Groups. The key improvement lies in keeping the indexing data local to the Hudi tables, thus avoiding the cost of operating an extra server. Please refer to this blog for a detailed discussion.
Recap
In this post, we discussed Hudi indexing APIs for writers, delved into the detailed flows of the Simple Index and the Bloom Index, and briefly introduced the Bucket Index, the HBase Index, and the Record Index. Please feel free to share your feedback and suggest content in the comments section.
Apache Hudi has a thriving community - come and engage with us via Slack, GitHub, LinkedIn, X (Twitter), and YouTube!
This is one of the best blog available in the internet RN wrt Hudi
Isn't bloom the default index?