


Apache Hudi: From Zero To One (7/10)
Concurrently run writers and table services

Apache Hudi: From Zero To One
In the previous post, we concluded our discussion on table services by exploring the intricacies of the clustering process and space-filling curves. With the knowledge gained in previous posts, we can seamlessly transition to the next topic: concurrency control, focusing specifically on managing concurrency for writers and table services.
A Primer on Concurrency Control
Every commit to a Hudi table is a transaction, whether it stems from adding new data or executing a table service job. Concurrency control is about orchestrating concurrently executed transactions to ensure correctness and consistency while maintaining optimal performance. A wealth of valuable resources is available online, such as this course and this paper. This primer aims to offer just enough context for the subsequent sections that delve into Hudi's implementation of concurrency control.
In databases, ACID are 4 essential properties to maintain the integrity and reliability of transactions. In the chart provided below, I've presented a brief summary of ACID, attempting to leave a clear and easily memorable overview.

Atomicity requires that each transaction be treated as an indivisible unit of work; any changes made by the transaction should be rolled back in the event of a halfway failure. Consistency is about application-specific constraints; for example, a primary key field cannot have duplicates, or the product price column must be non-negative. Isolation ensures concurrent transactions are isolated from each other, resulting in making changes as though they are executed sequentially. Durability mandates the preservation of committed data on storage, ensuring resilience against incidents such as hardware failures.
If the Isolation property is not honored, concurrent transactions will incur read and write anomalies, such as dirty read/write, lost update, etc. While enforcing a strictly serial execution of all transactions can eliminate the anomalies, this severely impacts performance, rendering the system practically unusable. Therefore, we should allow concurrent execution for performance, and coordinate them in equivalence to a serial schedule for correctness. In other words, what we need is a serializable schedule.
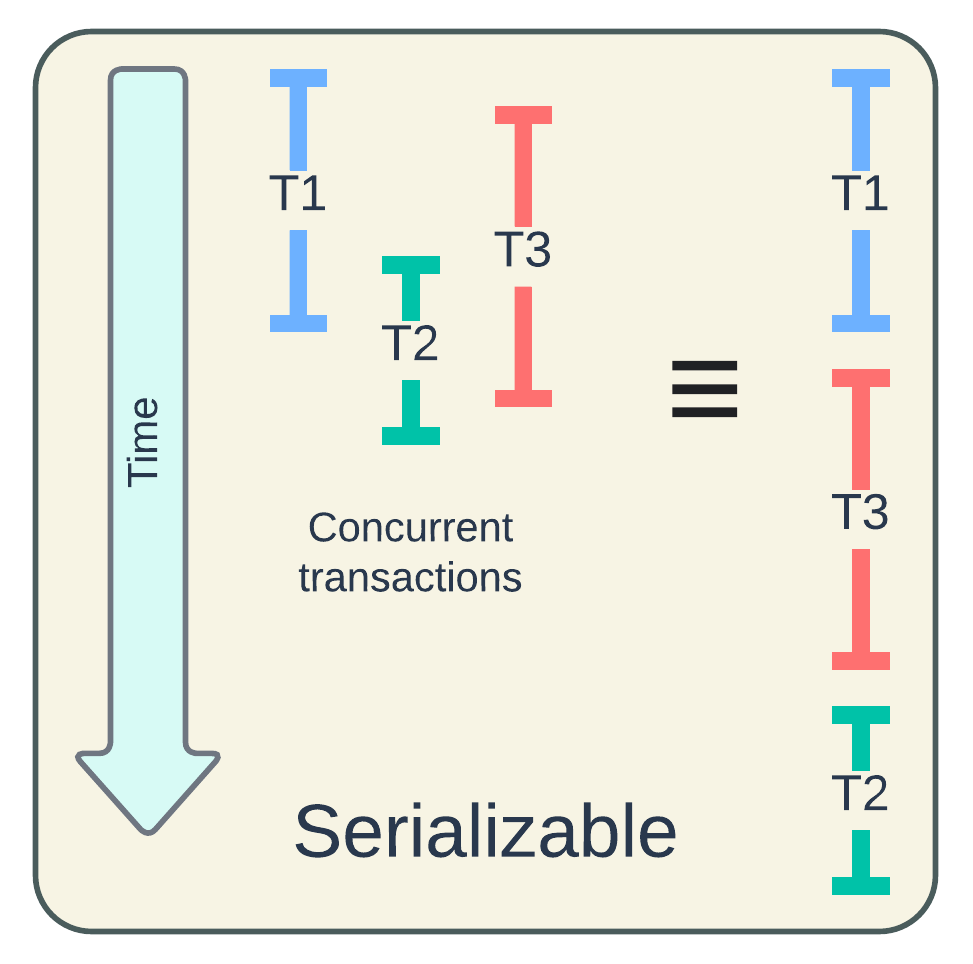
MVCC (Multi-Version Concurrency Control) and OCC (Optimistic Concurrency Control) stand out as two widely adopted strategies for enforcing serializable schedules in various database systems. MVCC keeps multiple record versions on storage and associates them with monotonically increasing transaction IDs (e.g., timestamps). OCC "optimistically" allows concurrent transactions to proceed on their own first and resolves any conflicts later. Hudi adopted MVCC for handling single writer with concurrent table services without locking. In later releases, OCC implementation was added to support multi-writer scenarios. In the upcoming sections, we will explore how Hudi employs these strategies in dealing with concurrent writers and table services.
MVCC in Hudi
Timeline and File Slices serve as the foundation to Hudi's MVCC implementation. Timeline uses monotonically increasing commit start time to keep track of transactions to the table. File Slices handle record versioning and correspond to transaction timestamps. One layer above these, Hudi constructs a view object, namely TableFileSystemView, providing APIs to return the table's most recent storage states, such as the latest File Slices under a partition path, and File Groups that undergo clustering. Writers and readers always consult the table file-system view for deciding where to perform the actual IO operations. This design provides read-write isolation out-of-the-box since the new data writing does not interfere with readers accessing past versions.
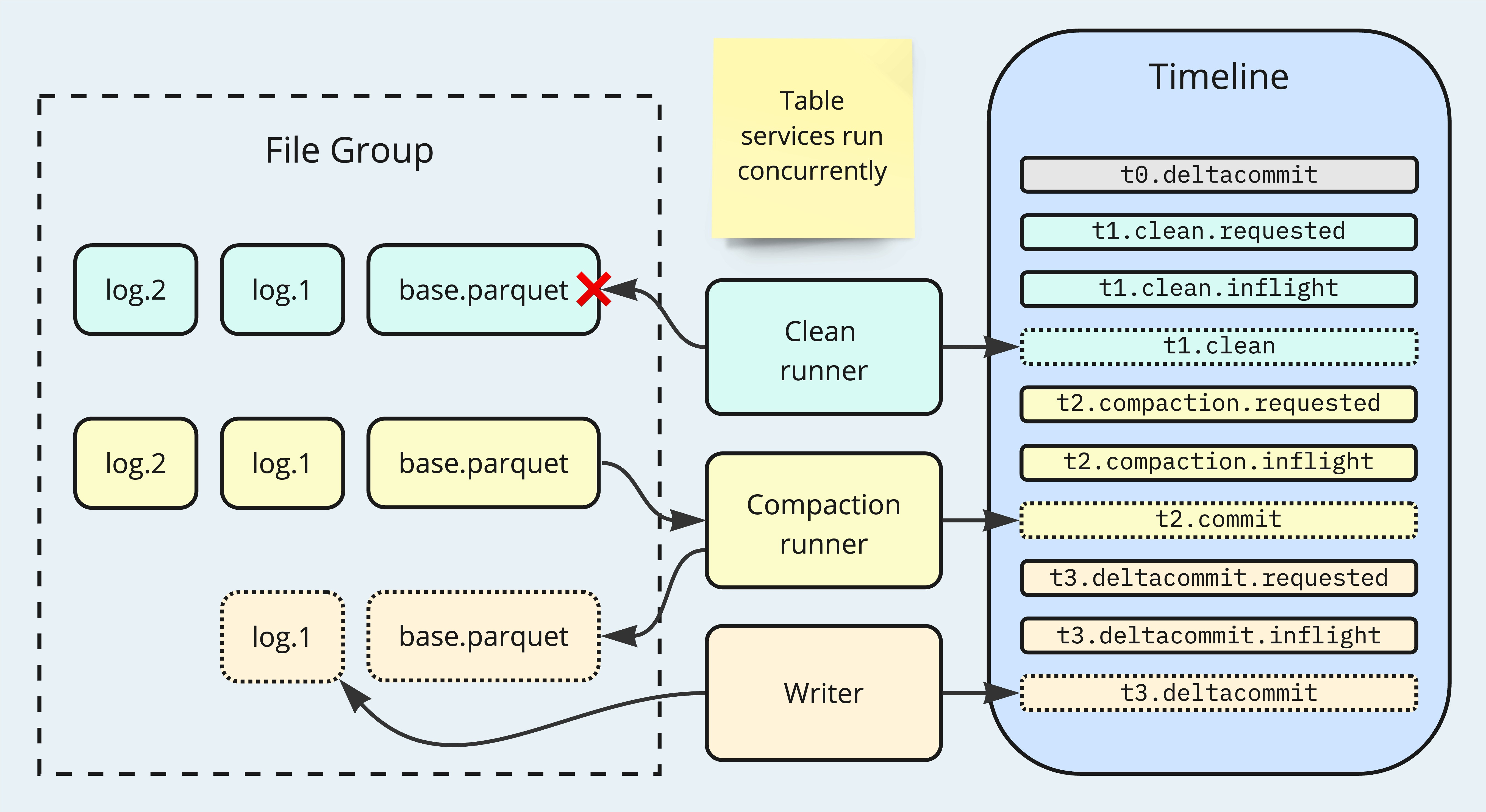
When a write operation is in progress, a commit action indicating this write will be marked as "requested" or "inflight" on the Timeline. This makes the table file-system view aware of the ongoing action, ensuring that table service planners do not include the File Slices currently being written for subsequent execution. This logic also holds true in the scenario of concurrent table service jobs. Hudi's table services are idempotent operations because the plans containing information about which File Slices to read are persisted. Therefore, retries in the event of failure won't impact the final result.
While a compaction could be on-going, any new write to the MoR table would either route new records to new File Groups or append updates/deletes to Log Files. The Base File that the compaction job is producing will be excluded by the view to prevent misuse. When clustering is pending, users can configure the writer's behavior in case of updating a File Group that undergoes clustering: abort the write, rollback the clustering, defer to later conflict resolution (OCC), or perform dual-write to both the source and target clustering File Groups. Cleaning is always executed in a way that retains the latest File Slices, keeping the deletes clear of new writes.
OCC in Hudi
An OCC protocol typically comprises of three phases: read, validation, and write. In the read phase, concurrent writers perform the necessary IO operations to complete their work in isolation. The validation phase involves collecting the list of changes from each writer and determine if any conflicts exist. Lastly, during the write phase, all changes will be accepted if no conflicts are found, or if conflicts arise, the changes from writer with the later transaction time will be rolled back. This is similar to the GitHub workflow, where contributors can submit pull requests to the upstream repository. The merging will be blocked for pull requests that have conflicts, akin to the validation phase in OCC.
As concurrent updates could lead to write anomalies, Hudi implements OCC at the file-level granularity to handle multi-writer scenarios. To enable this feature, users need to set "hoodie.write.concurrency.mode" to OPTIMISTIC_CONCURRENCY_CONTROL and configure a locker provider accordingly.1 The following diagram demonstrates how OCC is integrated into Hudi's write flow.
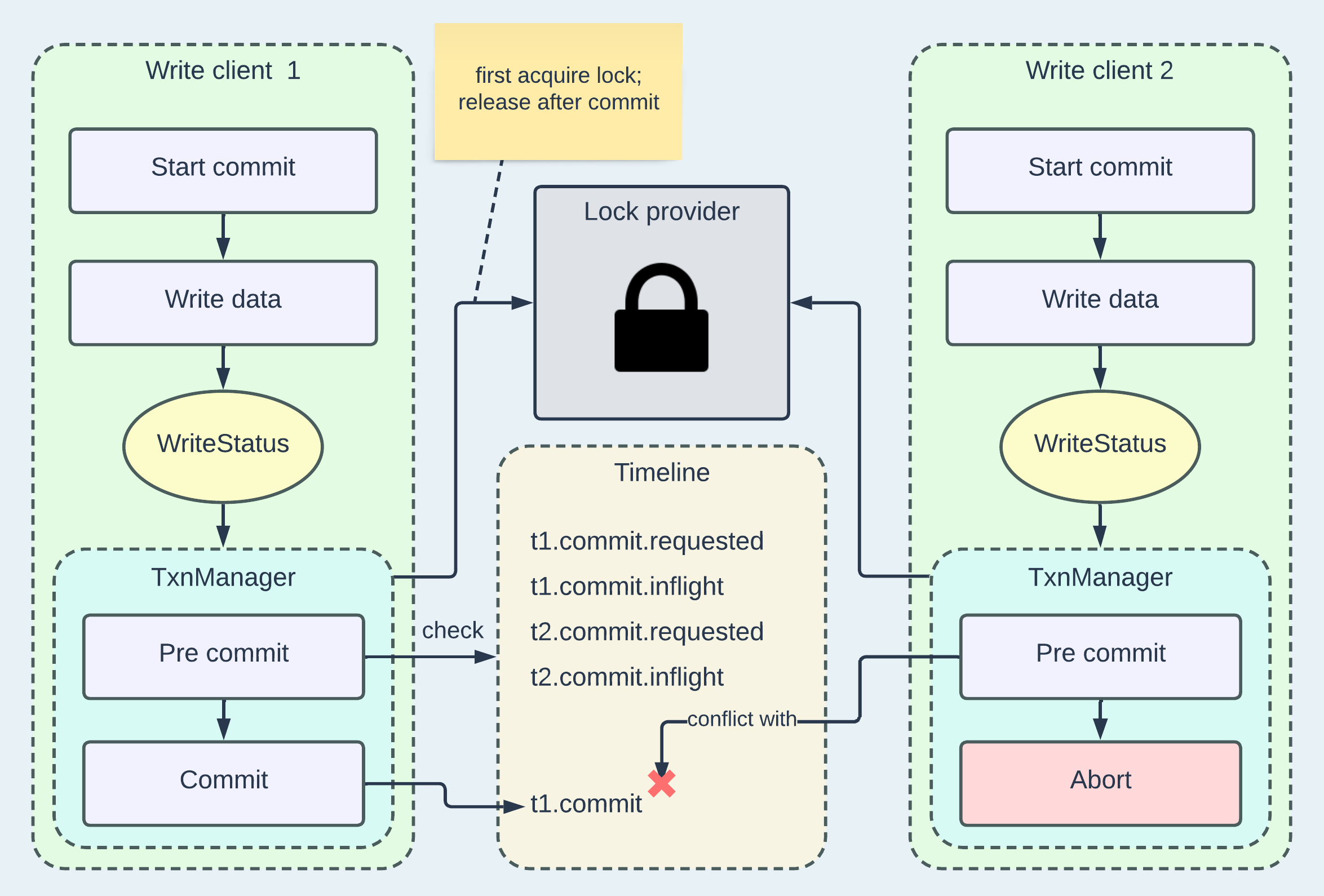
Highlight some key steps in the diagram:
Write client 1 is writing t1.commit and first acquires a lock from the lock provider, which is usually implemented using an external-running server such as Zookeeper, Hive Metastore, or DynamoDB.
While holding the lock, write client 1 can exclusively check the Timeline to see if any concurrent commits have been completed before its own attempt. In this example, t2.commit by write client 2 is the only candidate Timeline instant to check against and it's still inflight, therefore client 1 can proceed to commit and release the lock.
Write client 2 is writing t2.commit and acquires the lock after client 1 releases it. In the pre-commit phase, the changed files by client 2, obtained from WriteStatus, conflict with the changed files by client 1, derived from t1.commit. Consequently, client 2 will abort the write.
Aborted writes will be rolled back, implying the deletion of all the written files, both for data and metadata, as if the writes never occurred. While this fulfills Atomicity in the ACID properties, it could also be wasteful, particularly when the conflict chances are high. Hudi offers an early-conflict-detection mode for OCC. In this mode, before the actual files are written, lightweight marker files are created in a temporary folder. These markers serve as a preliminary step for conflict checking. For a detailed explanation of the design and implementation of early conflict detection, please refer to this community talk.
Recap
In this blog post, we went through a brief overview of the concurrency control topic before delving into the implementation details of two strategies, MVCC and OCC, within Hudi. These strategies are adeptly employed to address scenarios involving a single writer with table services and multiple writers. Please feel free to share your feedback and suggest content in the comments section.
Apache Hudi has a thriving community - come and engage with us via Slack, GitHub, LinkedIn, X (Twitter), and YouTube!
Readers may refer to the official documentation page for more details on enabling multi-writing.