


Apache Hudi: From Zero To One (8/10)
Read and process incrementally

Apache Hudi: From Zero To One
In this post, we will explore the topic of incremental processing in Hudi, addressing the missing piece mentioned in post 2. We'll start with a concise overview of the incremental architecture before examining two related features in Hudi: incremental query and change data capture (CDC).
Overview
Incremental processing, a technique of extracting, loading, and transforming (ELT) subsets of data to keep end results up-to-date, has become a standard in constructing data pipelines for data lakehouses. Unlike traditional methods, which often involve pulling a complete data snapshot for storage overwriting or using costly join operations to identify updates, modern data lakehouses typically utilize a storage format inherently supportive of incremental processing to simplify the architecture. Benefiting from the native support, the medallion architecture has gained popularity and has been adopted in production pipelines by numerous companies. This architecture is characterized by three key layers: the bronze layer, essential for reprocessing needs; the silver layer, ensuring data quality; and the gold layer, delivering business value.

In the next sections, we'll discuss how Hudi achieves incremental processing, which is well-suited to supporting a robust implementation of the medallion architecture.
Incremental Query
Hudi effectively tracks changes in the form of transaction logs by persisting commit metadata within the Timeline, and thereby naturally facilitates incremental processing which, in most cases, relies on timestamp-based checkpointing. Hudi's incremental query feature is enabled through these configurations:
hoodie.datasource.query.type=incremental
hoodie.datasource.read.begin.instanttime=202305150000
hoodie.datasource.read.end.instanttime=202305160000 # optionalThese allow for the retrieval of data that has changed within a defined time window. For more usage examples, please check out the documentation page. A few things to note on the behaviors:
Setting
hoodie.datasource.read.begin.instanttime=0effectively requests all changes made to the table from the very beginning of its history.Omitting
hoodie.datasource.read.end.instanttimewill result in fetching the changes up to the most recent completed commit in the table.The data returned by incremental queries contains records that were updated during the specified time window1. These records are matched to their versions corresponding to the latest completed commit in the table. If
hoodie.datasource.read.end.instanttimeis set, the records will align with the commit denoted by this specified end time.When the begin time is set to 0 and the end time is omitted, the incremental query effectively becomes equivalent to a snapshot query, retrieving all the latest records in the table.
Now that we have an understanding of the behavior of incremental queries, we are prepared to delve into the details. The following diagram shows the workflow involved in fetching incremental data from a Hudi MoR table.
Incremental queries follow the read flow as depicted in post 2, implementing two internal APIs: collectFileSplits() and composeRDD(). The implementation is largely divided into these steps:
collectFileSplits()is responsible for identifying all files relevant to the query. This function derives start and end timestamps based on user input to define a specific time range. This time range is then used to filter commits on the Timeline.Hudi's Timeline, comprising a series of transaction logs, inherently represents the changes made over time. With a specified time range, it becomes straightforward to filter down to the relevant files needed for the
composeRDD()function to process.In a Hudi table, each record includes a metadata field named
_hoodie_commit_time, which links the record to a specific commit in the Timeline. During the process of loading target files for records, incremental queries construct a commit time filter to further minimize the amount of data read. This filter is pushed to the level of file reading, allowingcomposeRDD()to be optimized to load only those records that are intended to be returned.
Change Data Capture
Incremental queries effectively reveal which records have been changed and their final states. However, they don't provide specific details about the nature of these changes. For instance, if record X is identified as having been modified, the incremental query doesn't clarify its column values prior to the update, or whether it was a newly inserted record. Additionally, it doesn't indicate if any records were hard-deleted. To address these limitations, Hudi 0.13.0 introduced Change Data Capture (CDC). This enhanced format of incremental processing provides a more comprehensive view of data modifications, including inserts, updates, and deletes, thereby enabling a clearer understanding of the changes within the dataset.
To enable the CDC functionality, users need to set this table property hoodie.table.cdc.enabled=true2. Writers writing to the table will honor this setting and activate the process of creating CDC log files alongside Base Files. Thanks to Hudi's file grouping mechanism, these CDC log files are included in the same File Groups that hold the changed data. This makes it easy to extend table services like cleaning, and facilitate recovery operations like restore, to manage both CDC log files and data files altogether for more coherent file management.
To pull the CDC data, users just need to set the incremental format to CDC when performing incremental queries. Time-range related behaviors still apply to the CDC query format.
hoodie.datasource.query.type=incremental
hoodie.datasource.query.incremental.format=cdc
hoodie.datasource.read.begin.instanttime=202305150000
hoodie.datasource.read.end.instanttime=202305160000 # optionalThe following diagram shows a brief overview of how writer and reader interact with CDC files and data.
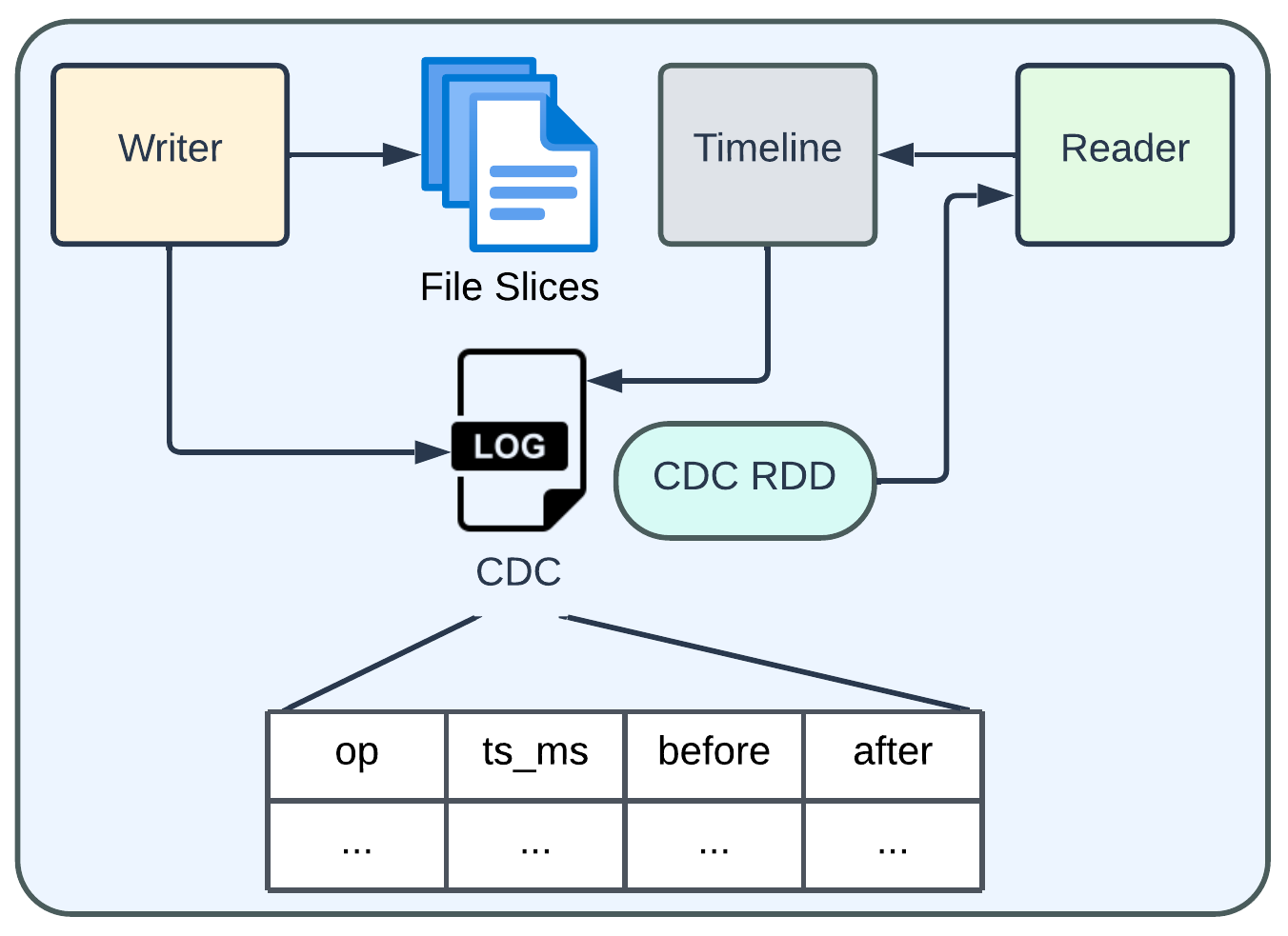
On the writer side, Hudi's write handle holds the information3 about the intended operations for the writing records (insert, update, or delete). This information is then encoded into a specific CDC log file format, containing four fields as shown in the diagram. The nullable "before" and "after" fields store the complete record snapshot before and after the change. Users have the flexibility to reduce the volume of logged data by adjusting hoodie.table.cdc.supplemental.logging.mode: use DATA_BEFORE to skip the "after" field, or set OP_KEY_ONLY to store record key instead of "before" and "after" fields.
On the reader side, CDC log files are loaded to construct the results, following a process similar to that of normal incremental queries (whose incremental format is called latest_state). If both "before" and "after" fields are logged, the results will be directly extracted from the CDC log files. In case of a less verbose logging mode is used, the results will be computed on-the-fly by looking up existing records in the table. This is essentially a trade-off between saving storage space and the efficiency of running CDC queries.
Richer Insights
The introduction of CDC capabilities greatly enhances Hudi tables' usage, supporting a wider range of scenarios and offering valuable insights. Take, for example, an account balance subject to frequent debit and credit transactions. Without CDC, periodic snapshot queries or the latest_state incremental queries might only see small or no change in the balance, potentially missing critical fluctuations. Through CDC queries, all changes are revealed, offering a comprehensive view of the account's activities. This level of details would be essential to enable fraud detection algorithms to take actions accordingly.
Recap
In this post, we provided a concise introduction to incremental processing and the medallion architecture, followed by an in-depth exploration of Hudi's approach to supporting incremental queries and Change Data Capture (CDC). Finally, we discussed the significance of CDC in deriving valuable business insights. Please feel free to share your feedback and suggest content in the comments section.
Apache Hudi has a thriving community - come and engage with us via Slack, GitHub, LinkedIn, X (Twitter), and YouTube!
The updating actions and the time window here correspond to the processing time in the Hudi table, not the event time in the business domain.
Once enabled, users are not allowed to switch the setting on and off during the table's lifespan. This restriction is enforced due to its impact on the storage layout and the usecase being undesirable to accommodate the flexibility.
Depending on the execution engine and the index configuration, either writer or compaction runner has access to this information.