


Apache Hudi: From Zero To One (5/10)
Introduce table services: compaction, cleaning, and indexing

Apache Hudi: From Zero To One
The previous four posts in this series have delved into the details about read and write, offering ample context to the new topic addressed in this post, i.e., table services. The following content will be divided into two parts: the first segment will introduce the high-level concepts of table services, while the second part will cover three specific table services - compaction, cleaning, and indexing.
Overview
Table services can be defined as a type of maintenance job that operates on a table without adding new data. When ingesting new records, we often prioritize low latency, which may lead to making trade-offs and leave storage sub-optimized. Running table service jobs results in an improved storage layout, paving the way for more efficient read and write processes in the future.
A table service job comprises two steps: scheduling and execution. The scheduling step aims to generate a plan of execution, while the execution step carries out the plan and makes actual changes to the table. We can categorize the methods of running table services in Hudi into three modes: Inline, Semi-async, and Full-async, as depicted below, to provide flexibility for various real-world scenarios.
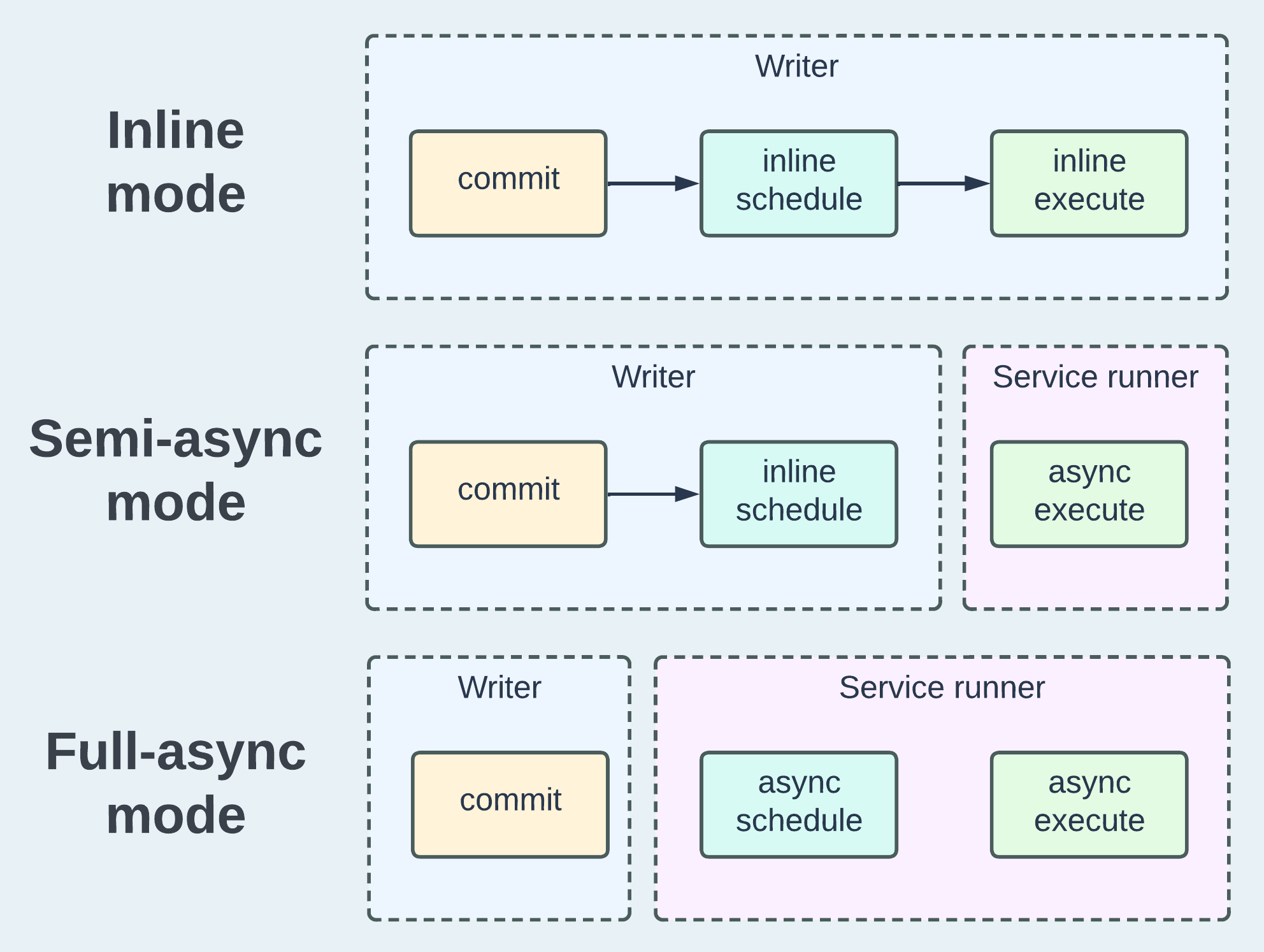
In the inline mode, both "schedule" and "execute" occur synchronously after the writer commits, making them "inline". This requires the simplest operational effort, as the two steps are automatically executed in sequence within the existing writer process. However, as an evident trade-off, it may introduce significant latency to the writing process.
The semi-async mode maintains inline scheduling and separates execution from it, i.e., execute asynchronously to the writer process. In this mode, users have the flexibility to deploy the service runner as a separate job or even to a different cluster, which might be necessary due to high computational requirement of the service execution.
The full-async mode is the most flexible mode that decouples table service running from writer processes. This is particularly helpful in managing a large number of tables in a lakehouse project, where a dedicated scheduler can be employed to optimize both scheduling and execution.1
As of release 0.14.0, Hudi offers four table services: compaction, clustering, cleaning, and indexing. In the following sections, we will explore compaction, cleaning, and indexing, reserving clustering in a subsequent post.
Table Services
Compaction
Recall from post 1 on storage layout that a File Slice can contain multiple Log Files and a Base File in MoR tables. As new data comes in, we evolve the File Slice by merging all Log Files against the Base File, creating a new version of the File Slice represented in a new Base File. This process is called compaction and is specific to MoR tables. However, this doesn’t apply to CoW tables, as new Base Files are generated automatically upon writes and have no Log Files to undergo compaction.
There are quite a few configurations to manage when scheduling and executing compaction. The official documentation provides detailed examples that showcase the usage. In this post, our focus is on the generalized internal workflow illustrated in the diagram below.
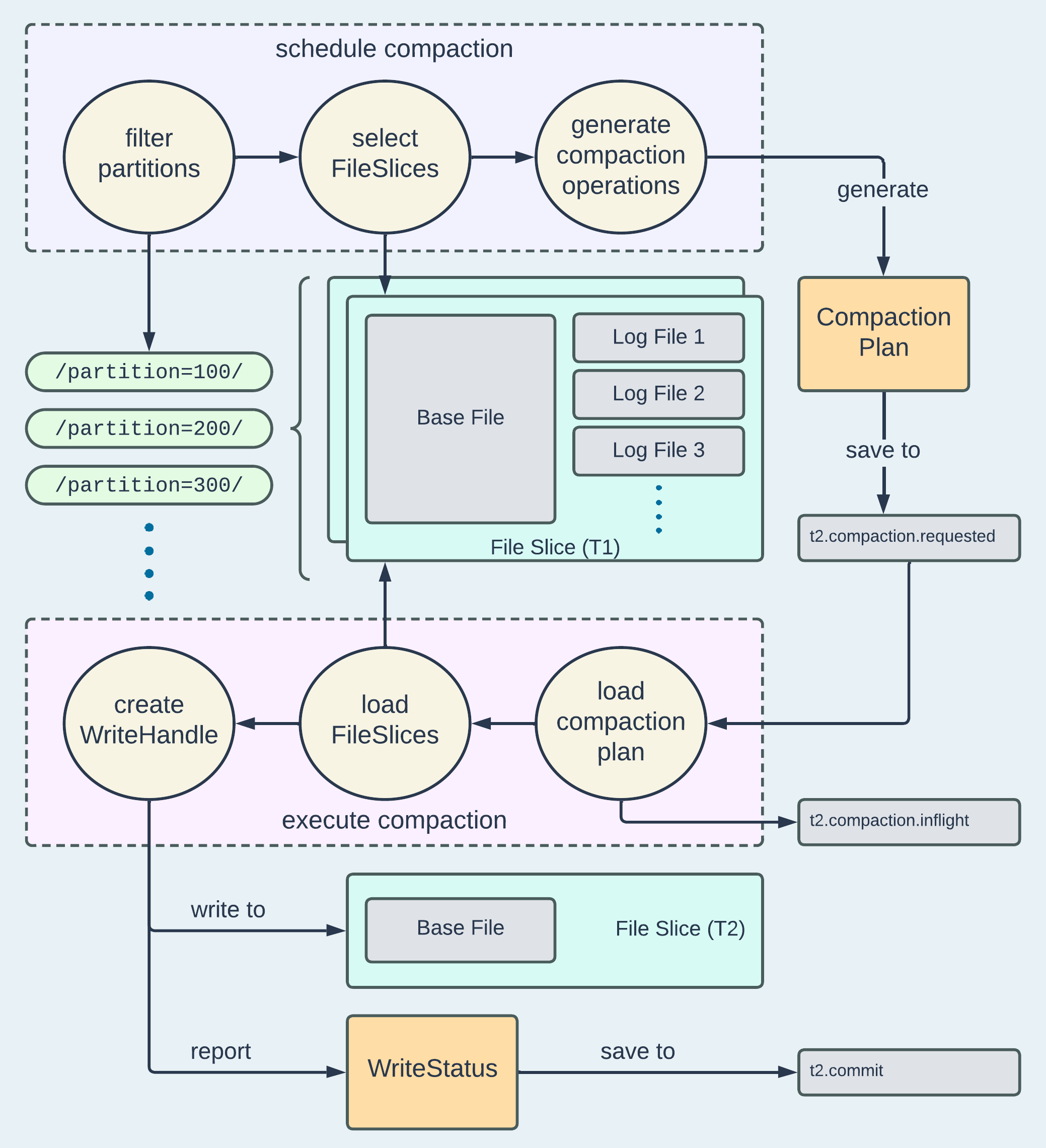
The scheduling step determines whether compaction is necessary based on the configurable CompactionTriggerStrategy. If deemed true, it generates a compaction plan and saves it to the Timeline as a .compaction.requested action. Users can set the triggering threshold based on factors such as number of commits or elapsed time. If the criteria are met, a compaction plan generator will scan the table based on the CompactionStrategy, which essentially controls which File Slices should be compacted, and produces CompactionOperation for each File Slice to formulate a plan.
The execution step loads all the serialized CompactionOperation from the plan and runs them in parallel. Depending on the presence of the Base File in the target File Slice, either MergeHandle or CreateHandle will be used to write the merged records in a new File Slice. Similar to a write process, a group of WriteStatus will be returned, reporting statistics collected during the execution, and a .commit action will be saved on the Timeline, marking the success of the compaction.
Compaction jobs can be quite resource-intensive due to the high write-amplification when re-writing Base Files. An experimental table service named Log Compaction2 was initially introduced in release 0.13.0 to address the write-amplification issue by only compacting Log Files into larger ones.
Cleaning
For incoming data, Hudi tables continually add File Slices to represent newer versions, taking more disk space. Cleaning is the table service designed to reclaim storage space by deleting old and unwanted versions. For detailed usage information, please refer to the documentation page.

Similar to compaction, Hudi utilizes CleaningTriggerStrategy to determine if cleaning is required at the time of scheduling. Currently, the only supported triggering criterion is the number of commits. After N commits (as configured), a cleaning planner will scan relevant partitions and determine if any File Slice meets the criteria for cleaning, as defined by HoodieCleaningPolicy. Physical paths of either Base Files or Log Files from the eligible File Slices will be used to generate a group of CleanFileInfo. A cleaning plan is then formulated based on that and saved into a .clean.requested action. As of now, three cleaning policies are supported: clean-by-commits, clean-by-file-versions, and clean-by-hours.
The cleaning execution is relatively straightforward: after loading the plan and deserializing the CleanFileInfo, the job performs file-system deletes for the target files in parallel. Statistics are initially collected at the partition level, and then aggregated and saved into a .clean action, indicating the completion.
Indexing
The indexing table service was first added in release 0.11.0 as an experimental feature. Currently, it is designed for building indexes for the metadata table. We will refrain from delving into the indexing process as it requires prior knowledge of the metadata table. Instead, I will provide a brief overview of the design. For further learnings, I recommend consulting the official documentation, this blog, and RFC-45.
In post 4, we mentioned an indexing API named updateLocation() that is required by certain indexes to keep the indexing data in sync with the written data. From a table service perspective, we can view it as indexing running in inline mode, i.e., scheduled inline and executed inline. The current indexing service is considered as being in full-async mode. The metadata table can be seen as another index type that encompasses multiple indexes, also known as a multi-modal index. As the data table size grows, updating the metadata table inline with each write can be time-consuming. Therefore, we need the async table service to maintain high write-throughput while keeping the indexes up-to-date.
Recap
In this post, we introduced the concept of table service, delved into the detailed processes of compaction and cleaning, and briefly touched on indexing. Please feel free to share your feedback and suggest content in the comments section.
Apache Hudi has a thriving community - come and engage with us via Slack, GitHub, LinkedIn, X (Twitter), and YouTube!
The on-going RFC-43 table service manager is designed to support this platform feature out-of-the-box.
Great series - thanks for writing this!
Does compaction is not needed for COW tables?